* Some of the images above are being generated live in the browser, and are unique to you and only you
Making a machine generate (dream, hallucinate, ...) natural images is a lot of fun, and quite complicated.
The lead up
About two months ago, we decided to try something that's been at the back of our heads since Ian Goodfellow first presented (the awesome) Generative Adversarial Networks at NIPS last year. Ian's work came close to generating natural-ish images, but still fell short in terms of image quality. The paper excited us, and we discussed it to length at the conference and after.
Adversarial networks are fun things.
You pit a generative (G) machine against a discriminative (D) machine and make them fight. The G machine attempts to produce fake data that looks so real that the D machine cannot tell it is fake. The D machine is learning to not get fooled by the G machine. After these have played their minimax game, you hope to get a good quality generator that can generate as many real looking samples as you want.

Street Fighter as an analogy for Adversarial Nets.
Two networks fight against each other,
and slowly get better at the game after playing long enough
The research process
First steps: making Goodfellow's neural network bigger and deeper
To keep this section brief, this did not work. It didn't work at all. The adversarial training was more unstable, and when we did get a stable model, it did not improve image sample quality.
Next try: multi-scale generators
The key idea that got us going was to train a Laplacian pyramid of networks, each network predicting the next finer scale. What that means in simpler terms is that the network at a particular scale gets the coarsened version of the image to predict, and generates the refinement necessary to reconstruct the original image.
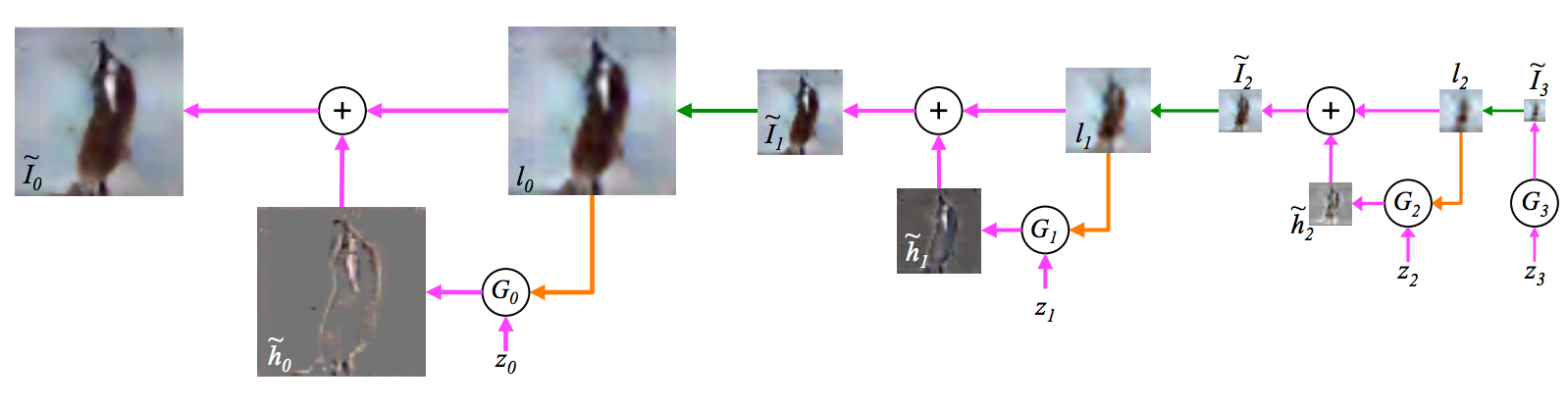
Each network Gx generates the difference image, when added to the input image, gives a finer-scaled image.

Who in their right mind works on generating bedrooms?

Skylines and bridges
The illusion of objectness
The multi-scale generation worked extremely well. It got us to a point where we had samples that looked much more real than previous attempts at generating such samples. However, there was one problem.
The images always looked object-like, but had no actual object.
Looking at the image at a glance would totally wow you, but looking closer, you'd be scratching your head. This wasn't going as well as we'd hoped, we needed another advance to get us closer to generating objects that actually were objects.
Some fun!
Because our neural networks are convolutional in nature, we can recursively apply a particular generator over and over again to get images as large as we want. However, image statics vary quite a bit at each scale, especially in the lower octaves. You can also chain different generators trained on different datasets together. For example, you can train a generator on a cats dataset, and chain it in the next scale with a generator trained on horses. It would be fun to try that.

256x256 images generated recursively. The network has never learnt to generate beyond 32x32 pixels, so you see some watercolor effects :)
Finally: Class-conditional, multi-scale generators
Our last idea, which was a fairly natural extension for us to enforce explicit objectness, was to pass to the G networks not only an input random noise, but also a one-hot coding of the class label we want to generate.
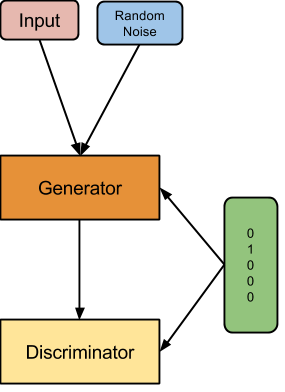
Class-conditional generative adversarial network
This idea finally nailed it home in terms of objectness of our generated output. We trained in on the CIFAR-10 database to produce cool looking horses, cars, airplanes etc.

Class-conditional CIFAR-10 28x28 generations
Another simplification that we did for training the LSUN database (because it is large enough, and because we were running against a conference deadline) is that we trained a separate network for each class. That also produced nice towers, bedrooms, churches and conference rooms.

Generated Church Outdoors of 64x64 pixels in size
Checking network cheating
One of the easiest thing a generative network can do to generate realistic samples is to simply copy the training images. This is not a true generative model that generalizes to all natural images, but one that overfit heavily on the training set. This is something we meticulously checked while training our networks, i.e. that our network is simply not copying the training samples. We've done this in a couple of ways.
Nearest neighbors using L2 pixel-wise distance
For each of our generated sample, we found it's nearest neighbor in the training set using a L2 distance in pixel space. For a large sheet of samples showing the nearest neighbors in pixel space, click here
Nearest neighbors using L2 feature-space distance
For each of our generated sample, we found it's nearest neighbor in the training set using a L2 distance in feature-space using this well-performing Network-in-Network CIFAR model . For a large sheet of samples showing the nearest neighbors in feature space, click here
Both the experiments comfortably concluded that our networks are generating images that are not just trivial manipulations of copied training images.
Resampling starting from the same initial image
Drawing samples conditioned on the same initial image gives us the ability to see if the variability
in producing the samples is trivial (copying), or non-trivial.
We did a few experiments on the LSUN database and concluded that our samples are fairly different
for every draw. For example, The network changes the building architectures, places and removes
windows, adds extra tunnels and hulls (and sometimes extra towers) and creates details that are
different everytime a sample is drawn.



Drawing multiple samples, conditioned on the same initial image. Churches, conference rooms, dining rooms
A few last details
- Adversarial training was hard to get right. Changing the model a little bit, or changing the learning rates a little bit made the network not learn anything at all.
- Using batch normalization in the discriminative network makes the whole adversarial training not work.
- We developed a few thumb rules like keeping the total number of parameters in the D network to be a 0.5 or 0.125 factor of the total number of parameters in the G network.
Details of our models
Each of our generative and discrimnative models were standard Convolution Neural Networks between 3 to 6 layers. For the complete architectural details, go to this link for CIFAR-10 and this link for LSUN/Imagenet
Where do we go from here?
There are so many things to explore, as follow-up work to this paper. A list of simple ideas would be:
- instead of one-hot coding, give word-embeddings as the conditional vector. Imagine the awesomeness of going from image captions to images.
- Apply the same exact method to generate audio and video
- Develop better theory and more stabilized training of adversarial nets.
Code etc.
The training code (in torch) is located here: https://github.com/facebook/eyescream